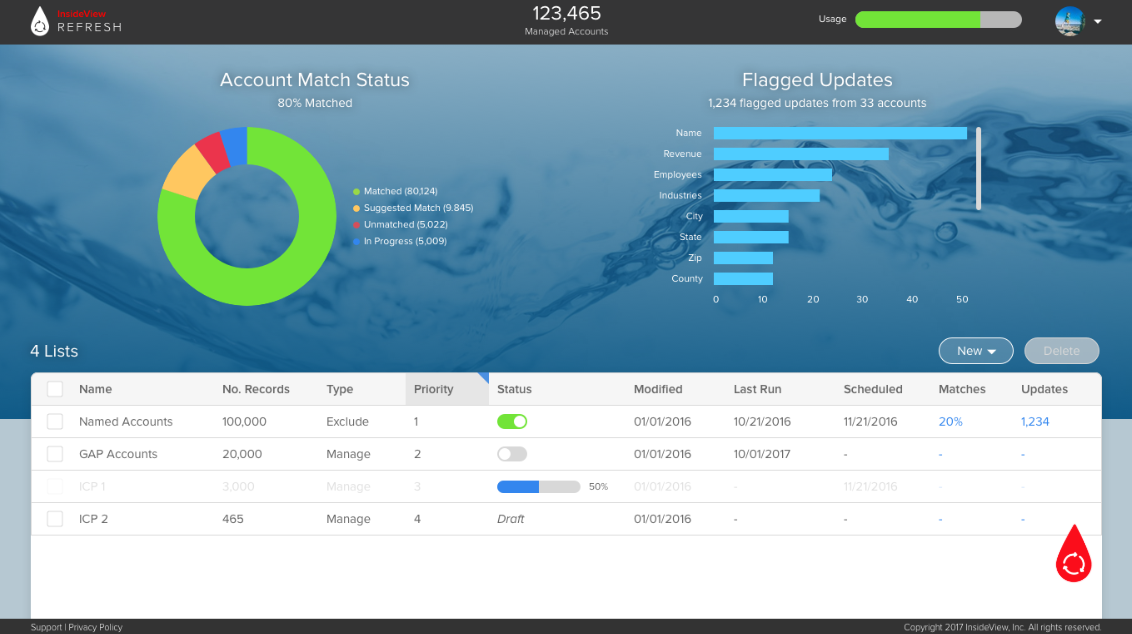
Scoped, provided outside in knowledge through partnerships / OEM vendors, and developed monetization strategy for Entity matching / record linkage as-a-service. Migrated from rule based record linkage to ML based models (random forest & logistic regression) using hadoop and spark applications with 20% increase in F1 and 40% increase in recall while maintaining 90% precision. Core features include:
- Tokenization: Significant prediction, segmentation, run together parsing, ordering, stop words
- Transformation: entity names, address, phone, and url canonicalization
- Business Taxonomies: Abbreviations, acronyms, alternate names, word expansions, misspellings, internationalization
- Feature blocking: tokenization, fuzzy (ratio, token set ratio, token partial ratio)
- Context: Family Tree (subsidiaries, corporate linkages)
Increase content extraction and yield by ~100%; enabled data cleansing applications (workflow and API ) with monetization of $1.1M in ACV in first 18 months (2016).